

안녕하세요 카페인팀 누누입니다
이번에는 대량의 데이터를 DB에 넣는 과정을 최적화하는 과정에서 알게 된 내용을 공유하려고 합니다
이번 최적화의 목표
전기차 충전소에 대한 공공 데이터를 가져오고, 그 데이터를 DB 에 넣는 과정을 최적화해보자
대량의 데이터를 삽입하는 과정
저희 팀의 요구사항을 간단하게 정리하면 다음과 같습니다
- 대량의 데이터를 공공 데이터에서 전기차 충전소와 전기차 충전기에 대한 데이터를 가져온다
- 충전소는 6만 개, 충전기는 23만 개의 데이터가 존재한다.
- 한 번에 가져올 수 있는 양은 9999개 까지다.
- 이 데이터를 DB에 넣는다
- 충전소와 충전기는 1:N 관계이다
최적화 전은 어떤 상황이었는데?

위 사진을 잘 보시면 아실 수 있으시겠지만, 2000개를 저장하는데, 231.762 초가 사용되었습니다.
물론 출력을 위한 시간도 포함되었기에, 230초 정도라고 생각하셔도 좋습니다
1만 개라면? 231.762초 * 5 = 1,158.81초
23만 개라면? 1158.81 * 23 = 26,652.63초
시간으로 바꿔보면 7.4 시간이 걸린다는 것을 볼 수 있습니다
이 과정에서 볼 수 있는 문제점
- 데이터를 저장할 때마다, 새로운 Transaction 이 생성된다.
어떻게 개선할 수 있을까?
데이터를 저장할 때마다, 새로운 Transaction 이 생성되는 것을 방지하기 위해, 전체를 하나의 트랜잭션으로 묶는다
전체를 한 트랜잭션으로 묶은 버전

이 과정에서 2000개를 저장하는데 65초 가 사용되었습니다.
1만 개라면? 65초 * 5 = 325초
23만 개라면? 325초 * 23 = 7,475초
시간으로 바꿔보면 2시간이 걸린다는 것을 볼 수 있습니다
전체적으로 3배 정도 빨라졌습니다
이 과정에서 볼 수 있는 문제점
- 23만 개의 저장이 모두 한 트랜잭션이 되어서, 하나가 실패하면 23만개를 새로 저장해야 하는 상황에 처한다
어떻게 개선할 수 있을까?
23만개의 저장이 모두 한 트랜잭션이 되는 것을 방지하기 위해, 1만 개씩 영속화시킨다
1만 개가 한 트랜잭션으로 묶인 버전
성능상으로 개선한 부분은 그렇게 크지 않지만, 실패했을 때, 1만 개만 다시 저장하면 되기에, 훨씬 빠르게 복구가 가능합니다.
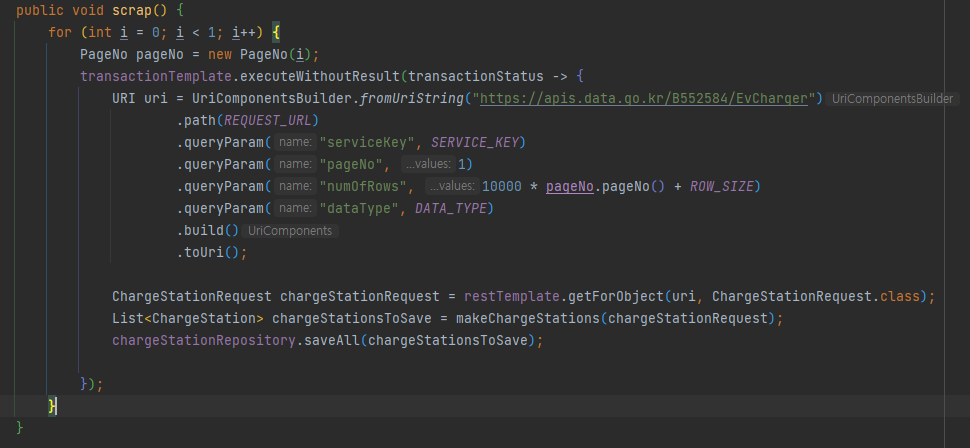
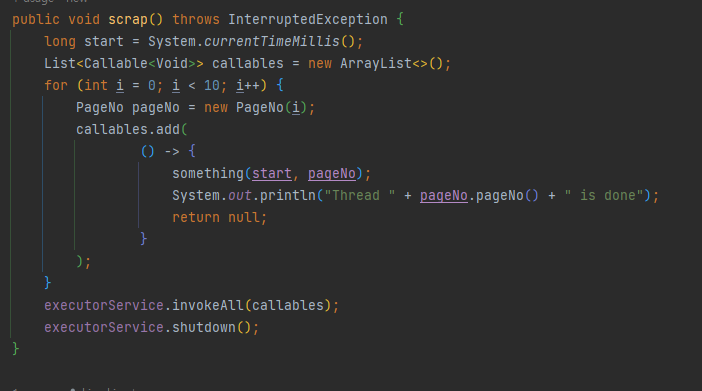
여기서 PageNo라는 클래스는, i를 바로 참조했을 경우, effectively final을 보장할 수 없어서 만들었습니다.
성능은 전체를 한 트랜잭션으로 묶은 버전과 큰 차이가 나지 않습니다.
이 과정에서 볼 수 있는 문제점
- id 생성 전략이
GenerationType.IDENTITY이기에, 데이터를 저장할 때마다, DB에서 id를 생성해야 한다.
JPA에 있는 쓰기 지연을 전혀 활용할 수 없고, DB에서 id를 생성하기 위해, DB와 매번 통신을 해야 한다.
어떻게 개선할 수 있을까?
id를 미리 생성해서, DB 에서 id 를 생성하는 과정을 생략한다
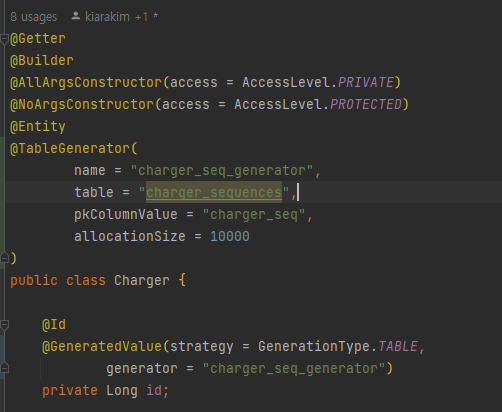
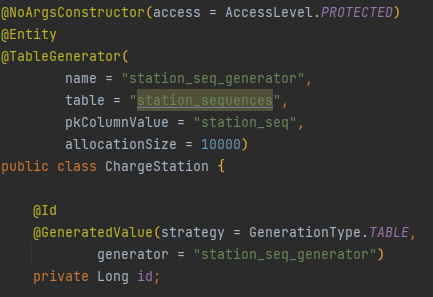
ID 생성 전략을 GenerationType.Table의 형태로 바꿔서, DB에서 id를 생성하는 과정을 줄여서, 성능을 개선한다
1만 개가 한 트랜잭션으로 묶이고, id를 미리 생성한 버전
이때 batch size를 1000 단위로 설정해서 1000개씩 id 가 늘어나도록 설정했다
spring.jdbc.template.fetch-size=10000
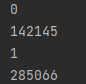
1자리 숫자는 앞에서부터 n(만개)를 의미하고, 2번째 숫자는 1만 개를 저장하는 데 걸린 시간(ms)을 의미합니다.
처음 1만 개는 142초가 걸리고, 2만 개는 285초가 걸렸습니다.
23만 개라면? 142 * 26 = 3,266초
처음과 비교하자면 7.4시간이 걸리는 것에서 54분 정도 걸리는 것으로 개선되었습니다.
이 과정에서 볼 수 있는 문제점
하나의 스레드에서만 동작하기에, 성능이 개선되었지만, 여전히 느립니다.
하나의 스레드에서만 동작하기에, 하나의 커넥션을 사용하게 됩니다.
어떻게 개선할 수 있을까?
여러 스레드에서 동작하게 하고, 여러 커넥션을 사용하게 합니다.
여러 스레드에서 동작하고, 여러 커넥션을 사용하는 버전
이 버전에서 89991 개를 저장하는데 총 157초가 걸렸습니다.
23만 개라면? 157 * 3 = 471초
시간으로 바꿔보면 5분도 채 걸리지 않는 시간이죠
이 과정에서 볼 수 있는 문제점
hikari connection pool 사이즈를 10으로 설정했는데, 10개의 커넥션을 사용하면서 저장을 하다 보니, 10개의 커넥션을 모두 사용하고 나서, 11번째부터는 커넥션을 가져오기 위해, 기다려야 하는 상황이 발생합니다.
어떻게 개선할 수 있을까?
hikari connection pool 사이즈를 25로 설정해서, 25개의 커넥션을 사용하도록 합니다.
spring.datasource.hikari.maximum-pool-size=25
여러 스레드에서 동작하고, 여러 커넥션을 사용하는 버전 2
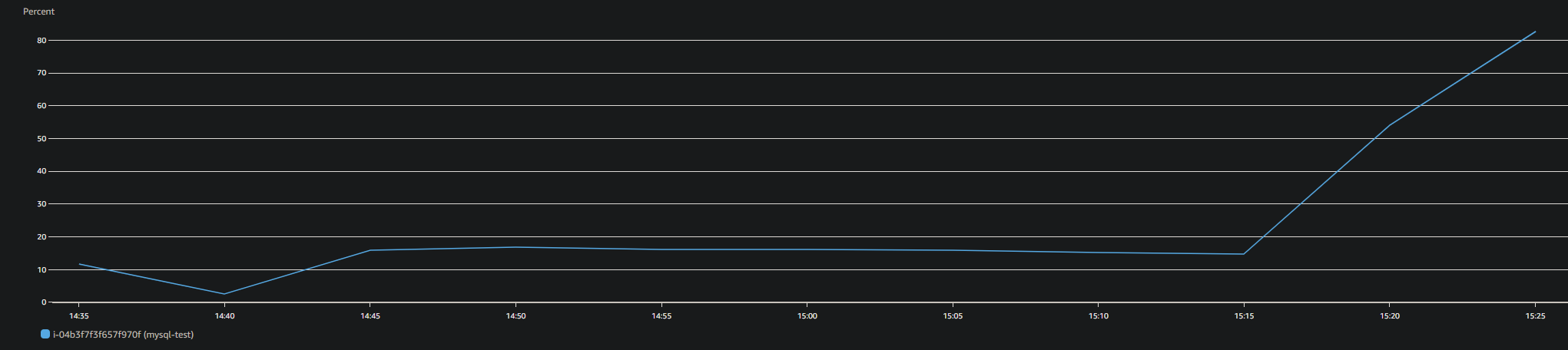
총 13만 개의 데이터를 저장하는데, 147초가 걸리고, db 인스턴스의 cpu 사용률이 100%에 가까워져서 ec2 가 다운되었습니다.
이 과정에서 볼 수 있는 문제점
db의 cpu 사용량을 고려하지 않고, 23만 개가 조금 넘는 데이터를 25개의 커넥션을 활용해 저장하려고 했습니다
결론
- 데이터를 저장할 때마다, transaction을 사용하지 말자
- 데이터를 저장할 때마다, id를 생성하지 말자
- 여러 스레드에서 동작하고, 여러 커넥션을 사용하자
- db의 cpu 사용량을 고려하자
긴 글 읽어주셔서 감사합니다